在web开过程中,经常会遇到高并发和资源共享的问题,这些问题的本质是:并行的请求转成串行。我们应该考虑的是怎么在尽可能提高吞吐量的情况下,保证资源的合理生产和消耗。
前置知识点
锁的实现的非权威解读
生活当中的锁原理其实很简单,传统的机械锁可以当作是一种机关,通过匹配形状齿轮触发机关某个部位而解锁。而现代的锁原理更简单,加锁其实就是设置一种状态,而要解除该状态只需要比对信息,比如数字密码、指纹等。
计算机中的锁,根据运行环境可以大体分为以下三类:
同一个进程。此时主要管理该进程的多个线程间同步以及控制并发访问共享资源。由于进程是共享内存空间的,一个最简单的实现方式就是使用一个整型变量作为flag,这个flag被所有线程所共享,其值为1表示已上锁,为0表示空闲。使用该方法的前提是设置(set)和获取(get)这个flag变量的值都必须是原子操作,即要么成功,要么失败,并且中间不允许有中断,也不允许出现中间状态。可幸的是,目前几乎所有的操作系统都提供了此类原子操作,并已经引入了锁机制,所以以上前提是可以满足的。
同一个主机。此时需要控制在同一个操作系统下运行的多个进程间如何协调访问共享资源。不同的进程由于不共享内存空间,因此不能通过设置变量来实现。既然内存不能共享,那磁盘是共享的,因此我们自然想到可以通过创建一个文件作为锁标记。进程只需要检查文件是否存在来判断是否有锁。
不同主机。此时通常跑的都是分布式应用,如何保证不同主机的进程同步和避免资源访问冲突。有了前面的例子,相信很多人都想到了,使用共享存储不就可以了,这样不同主机的进程也可以通过检测文件是否存在来判断是否有锁了。[机智表情]
以上介绍了锁的非权威实现,为了解释得更简单通俗,其实隐瞒了很多真正实现上的细节,甚至可能和实际的实现方式并不一致。要想真正深入理解操作系统的锁机制以及单主机的锁机制实现原理,请查阅更多的文献。
引子
我们经常遇到多进程/多线程的服务,以此来提高吞吐量,但是也会带来一些问题。
测试代码如下:main.py
1 | from json import dumps as json_dumps |
使用bottle默认wsgiref(单进程单线程)做基础代码,之后在此之上进行修改测试验证。
验证内容为: 往文件写内容,写的方式为:覆盖写。
使用就jmeter做并发测试
jmeter配置如下:
线程组:
- 线程数: 10
- ramp-up: 0
- 循环次数: 1
http请求: - 协议: http
- ip: 10.221.103.233
- port: 7000
- method: PUT
- url: /todos?index=${__Random(1,100,)}
1 service + 1 Process + 1 Thread
基础代码即为单服务单进程单线程.并发测试结果为:request返回值和写入的值相等。
结论:单服务单进程单线程天然串行,不存在并发问题,不需要锁控制。
1 service + 1 Process + n Thread
修改服务启动命令为:run(host='0.0.0.0', port=7000, server='paste', threadpool_workers=10)
使用paste作为server.paste使用线程池来实现。
并发测试结果为:request返回值和写入的值不一定相等。
1 service + n Process + 1 Thread
修改服务启动命令为:run(host='0.0.0.0', port=7000, server='gunicorn', workers=2)
使用gunicorn作为server.gunicorn使用pre-fork来实现, 实现类默认为sync。
并发测试结果为:request返回值和写入的值不一定相等。
1 service + n Process + n Thread
修改服务启动命令为:run(host='0.0.0.0', port=7000, server='gunicorn', workers=2, threads=2)
使用gunicorn作为server.gunicorn使用pre-fork来实现, 实现类默认为threads。
并发测试结果为:request返回值和写入的值不一定相等。
n service
- n service 部署在一个机器上, 每个service port 不同:可以通过nginx进行分发
- n service 部署在n机器上, 共享资源需要放到DB或者多个service访问某个指定位置的文件: 可以通过nginx进行分发
并发测试结果为:request返回值和写入的值不一定相等。
以上情况,只要存在并发就需要考虑资源抢占问题,就需要引入锁。
python内置线程锁
python线程锁: threading.Lock
装饰器实现线程锁
1 | import threading |
使用线程锁可以控制单进程多线程的并发。在jmeter测试之下,参数、返回结果、文件内容一致。
文件锁
使用fcntl模块实现文件锁,代码如下:
1 | def file_lock(f, lock_type=fcntl.LOCK_EX): |
由于lockf 绑定的是进程,所以只能用在多进程的时候进行加锁,在多线程中是不起作用的。
在Linux中有三个文件锁接口函数flock(…)、fcntl(…)、lockf(…),这三个接口可以创建Linux中不同类型的锁。下面简单介绍一下Linux中不同类型的锁
Linux中支持四种功能的文件锁:劝告锁、强制锁、租赁锁、共享模式锁,其中后两种锁都是强制锁的变种。
| 锁的类型 | 实现接口 | 锁的功能 |
|---|---|---|
| 劝告锁 | flock(…) fcntl(…) lockf(…) | 劝告锁是一种协同工作的锁。对于这一种锁来说,内核只提供加锁以及检测文件是否已经加锁的手段,但是内核并不参与锁的控制和协调。 |
| 强制锁 | fcntl(…) lockf(…) | 强制锁是一种内核强制采用的文件锁。每当有系统调用 open()、read() 以及write()发生的时候,内核都要检查并确保这些系统调用不会违反在所访问文件上加的强制锁约束。 |
| 租赁锁 | fcntl(…) | 租赁锁实际上是强制锁的变种,当进程尝试打开一个被租借锁保护的文件时,该进程会被阻塞,同时,在一定时间内拥有该文件租借锁的进程会收到一个信号。收到信号之后,拥有该文件租借锁的进程会首先更新文件,从而保证了文件内容的一致性,接着,该进程释放这个租借锁。如果拥有租借锁的进程在一定的时间间隔内没有完成工作,内核就会自动删除这个租借锁或者将该锁进行降级,从而允许被阻塞的进程继续工作。 |
| 共享模式锁 | flock(…) | 共享模式强制锁可以用于某些私有网络文件系统,如果某个文件被加上了共享模式强制锁,那么其他进程打开该文件的时候不能与该文件的共享模式强制锁所设置的访问模式相冲突。但是由于可移植性不好,因此并不建议使用这种锁。 |
关于flock(…)、lockf(…)、fcntl(…)的说明:
- flock(…):适用于劝告锁,只能实现对整个文件进行加锁,而不能实现记录级的加锁。但是flock实现了共享强制锁;
- fcntl(…):适用于劝告锁和强制锁,不仅能够对整个文件进行加锁,而且能够对文件中的记录(若干字节)加锁,实际上属于posix系列的锁。
- lockf(…):由于fcntl(…)函数功能非常多,文件锁只是其中一个。lockf(…)是fcntl(…)锁功能的包装。
数据库锁
数据库-乐观锁
乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在提交更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于读多写少的应用场景,这样可以提高吞吐量。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。
乐观锁一般来说有以下2种方式:
- 使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
- 使用时间戳(timestamp)。乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
Java JUC中的atomic包就是乐观锁的一种实现,AtomicInteger 通过CAS(Compare And Set,是一种自旋锁)操作实现线程安全的自增。
数据库-悲观锁
悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
Java synchronized 就属于悲观锁的一种实现,每次线程要修改数据时都先获得锁,保证同一时刻只有一个线程能操作数据,其他线程则会被block。
举例如下
假设,MySQL数据库中商品库存表tb_product_stock 结构定义如下:
1 | CREATE TABLE `product` ( |
悲观锁. SELECT ... FOR UPDATE
- sql语句写法
1
2
3
4
5
6
7
8
9
10
11public boolean updateStock(Long productId){
//先锁定商品库存记录
ProductStock product = query("SELECT * FROM tb_product_stock WHERE product_id=#{productId} FOR UPDATE", productId);
if (product.getNumber() > 0) {
int updateCnt = update("UPDATE tb_product_stock SET number=number-1 WHERE product_id=#{productId}", productId);
if(updateCnt > 0){ //更新库存成功
return true;
}
}
return false;
} - python sqlalchemy写法
1 | from sqlalchemy.engine import create_engine |
乐观锁.
- sql写法
1 | public boolean updateStock(Long productId){ |
- python sqlalchemy写法
1 | from sqlalchemy.engine import create_engine |
乐观锁与悲观锁的区别:
乐观锁的思路一般是表中增加版本字段,更新时where语句中增加版本的判断,算是一种CAS(Compare And Swep)操作,商品库存场景中number起到了版本控制(相当于version)的作用( AND number=#{number})。
悲观锁之所以是悲观,在于他认为本次操作会发生并发冲突,所以一开始就对商品加上锁(SELECT … FOR UPDATE),然后就可以安心的做判断和更新,因为这时候不会有别人更新这条商品库存。
sqlalchemy实现探究
with_for_update详解
SQLAlchemy 提供 with_for_update 函数 进行 锁的操作 .
1 | session.Query(User).with_for_update().first() |
完整形式为:with_for_update(read=False, nowait=False, of=None)
1 | - read |
在用SQLAlchemy对数据库操作的过程中出现这样一个现象,当在session.query()时,如果之前有session.add()操作,即使尚未进行commit操作,在query时也会查询到这个尚未真正插入数据库的对象
关于行锁和表锁
- 由于InnoDB 预设是Row-Level Lock,所以只有「明确」的指定主键或者其他索引的键,MySQL 才会执行Row lock (只锁住被选取的数据) ,否则mysql 将会执行Table Lock (将整个数据表单给锁住)。
- 只锁住被选取的数据的好处是:多线程时,如果其他线程使用的是非锁住的数据,则不会受影响,无需等待解锁,更好的实现了并发。
- select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。
- 在数据库内部update同一行的时候是不允许并发的,即数据库每次执行一条update语句时会获取被update行的写锁,直到这一行被成功更新后才释放。
- 另外:mysql的MyAsim引擎只支持表级锁,InnerDB支持行级锁
- MySQL InnoDB采用的是两阶段锁定协议(two-phase locking protocol)。在事务执行过程中,随时都可以执行锁定,锁只有在执行 COMMIT或者ROLLBACK的时候才会释放,并且所有的锁是在同一时刻被释放。
- MySQL隐式和显示锁定
- 隐式加锁
- InnoDB自动加意向锁。
- 对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁
- 对于普通SELECT语句,InnoDB不会加任何锁;
- 显示加锁:
- 共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE
- 排他锁(X) :SELECT * FROM table_name WHERE … FOR UPDATE
- 锁参考: https://blog.csdn.net/zcl_love_wx/article/details/81983267
- mysql索引参看 https://www.cnblogs.com/cq-home/p/3482101.html
openstack的多个组件,比如nova/cinder等都用到了锁来实现并发的控制。openstack 的oslo.* 模块是一个公用模块,一些常用的如下:
| 库名 | 作用 | 背景知识 |
|---|---|---|
| oslo.config | 配置文件 | 无 |
| oslo.utils | 工具库 | 无 |
| oslo.log + oslo.context | 带调用链的日志系统 | 无 |
| oslo.messaging | RPC调用 | amqp |
| oslo.service | 带ssl的REST服务器 | wsgi |
| oslo.db | 数据库 | sqlalchemy |
| oslo.rootwrap | Linux的sudo | 无 |
| oslo.serialization | 序列化 | 无 |
| oslo.i18n | 国际化 | 无 |
| oslo.policy | 权限系统 | deploy paste |
| oslo.middleware | pipeline | deploy paste |
| keystonemiddleware | 用户系统 | deploy paste + keystone |
| oslo_test | 测试 | unittest |
| oslo.concurrency | 多进程/线程管理 | threading/fcntl |
本文重点使用oslo.concurrency.
oslo.concurrency.lockutils
- InterProcessLock:进程锁。基于fasteners实现,fasteners根据操作系统具体实现有所区分,其中linux系统的实现是
fcntl.lockf - ReaderWriterLock:读写锁。读写锁实际是一种特殊的自旋锁(CAS:Compare and Set),它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。fasteners通过ReadWriterLock类实现了读锁和写锁,其在该类中定义了READER和WRITER标识分别表示申请的锁是读锁还是写锁。使用该类可以获得多个读锁,但只能存在一个写锁。在目前的版本中,该类不能实现从读写升级到写锁,且写锁在加锁时不能获取读锁;而以后可能会对这些问题进行优化。该类的主要方法如下:
read_lock():为当前线程申请一个读锁,其只有在没有为其他线程分配写锁时才能获取成功;如果另一个线程以及获取了写锁,调用该方法会返回RuntimeError异常。write_lock():为当前线程申请一个写锁,其只有在没有为其他线程分配读锁或写锁时才能获取成功;一旦申请写锁成功,将会阻塞申请读锁的线程。is_reader():判断当前线程是否申请了读锁。is_writer():判断当前线程是否申请了写锁,或已申请但尚未获得写锁。owner():判断当前线程是否申请了锁;如果获得了锁是读锁还是写锁。
ReaderWriterLock类中包含_writer属性表示占有写锁的线程,_readers属性表示占有读锁的线程集合,_pending_writers属性表示正在等待分配写锁的线程的队列,_current_thread属性表示当前线程,_cond属性表示threading.Condition对象。上述的这些方法就是通过操作这几个属性实现读写锁的。
- FairLocks: 读写锁。实现原理是基于python的
弱引用对象–weakref.WeakValueDictionary()实现的一个字典,字典的key是lock name,value是ReaderWriterLock对象。弱引用对象可以解决循环引用内存泄漏问题。 - Semaphores:线程锁。也利用了弱引用对象。只不过
WeakValueDictionary字典的value是threading.Semaphore(). - external_lock: 进程锁。核心还是
InterProcessLock,与InterProcessLock区别是可以自定义设置lock 文件的位置。 - remove_external_lock_file: 删除lock文件方法
- internal_lock: 线程锁。可以指定
Semaphore的具体实现方法,比如:eventlet.semaphore.Semaphore,如果没有指定,默认使用threading.Semaphore() - lock: 这个是一个综合方法,参数比较多,根据参数可以实现FairLocks、internal_lock、external_lock的其中一种。
- lock_with_prefix: 可以指定带有统一前缀的lock。目的是可以统一clean lock文件。调用lock来实现。
- synchronized: 是一个装饰器方法。封装lock方法。
其他方法不再一一列举,功能就是以上方法的再次封装运用。
分布式锁
分布式锁主要解决的是分布式资源访问冲突的问题,保证数据的一致性。使用共享存储文件作为锁标记,这种方案只有理论意义,实际上几乎没有人这么用,因为创建文件并不能保证是原子操作。另一种可行方案是使用传统数据库存储锁状态,实现方式也很简单,检测锁时只需要从数据库中查询锁状态即可。当然,可能使用传统的关系型数据库性能不太好,因此考虑使用KV-Store缓存数据库,比如Redis、Memcached等。但都存在问题:
不支持堵塞锁。即进程获取锁时,不会自己等待锁,只能通过不断轮询的方式判断锁的状态,性能不好,并且不能保证实时性。
不支持可重入。所谓可重入锁就是指当一个进程获取了锁时,在释放锁之前能够无限次重复获取该锁。试想下,如果锁是不可重入的,一个进程获取锁后,运行过程中若再次获取锁时,就会不断循环获取锁,可实际上锁就在自己的手里,因此将永久进入死锁状态。当然也不是没法实现,你可以顺便存储下主机和进程ID,如果是相同的主机和进程获取锁时则自动通过,还需要保存锁的使用计数,当释放锁时,简单的计数-1,只有值为0时才真正释放锁。
另外,锁需要支持设置最长持有时间。想象下,如果一个进程获取了锁后突然挂了,如果没有设置最长持有时间,锁就永远得不到释放,成为了该进程的陪葬品,其他进程将永远获取不了锁而陷入永久堵塞状态,整个系统将瘫痪。使用传统关系型数据库可以保存时间戳,设置失效时间,实现相对较复杂。而使用缓存数据库,通常这类数据库都可以设置数据的有效时间,因此相对容易实现。不过需要注意不是所有的场景都适合通过锁抢占方式恢复,有些时候事务执行一半挂了,也不能随意被其他进程强制介入。
支持可重入和设置锁的有效时间其实都是有方法实现,但要支持堵塞锁,则依赖于锁状态的观察机制,如果锁的状态一旦变化就能立即通知调用者并执行回调函数,则实现堵塞锁就很简单了。庆幸的是,分布式协调服务就支持该功能,Google的Chubby就是非常经典的例子,Zookeeper是Chubby的开源实现,类似的还有后起之秀Etcd等。这些协调服务有些类似于KV-Store,也提供get、set接口,但也更类似于一个分布式文件系统。以Zookeeper为例,它通过瞬时有序节点标识锁状态,请求锁时会在指定目录创建一个瞬时节点,节点是有序的,Zookeeper会把锁分配给节点最小的服务。
Zookeeper支持watcher机制,一旦节点变化,比如节点删除(释放锁),Zookeeper会通知客户端去重新竞争锁,从而实现了堵塞锁。另外,Zookeeper支持临时节点的概念,在客户进程挂掉后,临时节点会自动被删除,这样可实现锁的异常释放,不需要给锁增加超时功能了。
提供分布式锁服务的应用我们通常称为DLM(Distributed lock manager):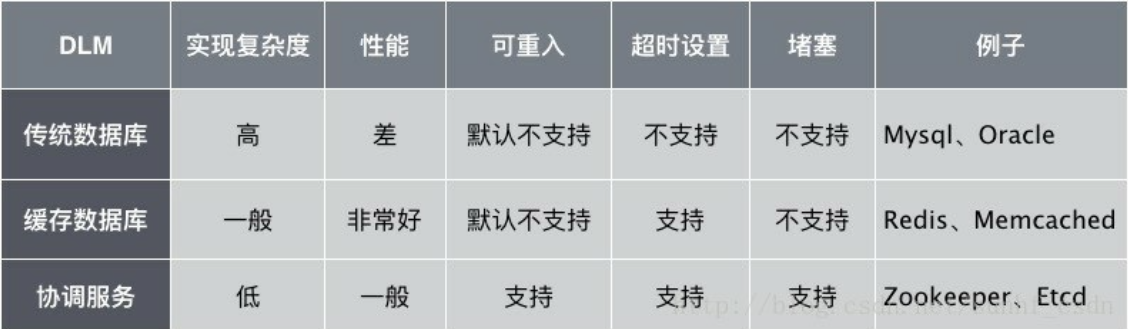
注: 以上支持度仅考虑最简单实现,不涉及高级实现,比如传统数据库以及缓存数据库也是可以实现可重入的,只是需要花费更多的工作量。
CAP概念
2000年Eric Brewer教授提出CAP猜想,2年后CAP猜想被Seth Gilbert和Nancy Lynch从理论上证明。CAP是Consitency(强一致性)、Availability(可用性)、Partition tolerance(网络分区容忍性)三个不同维度的组合体,如图所示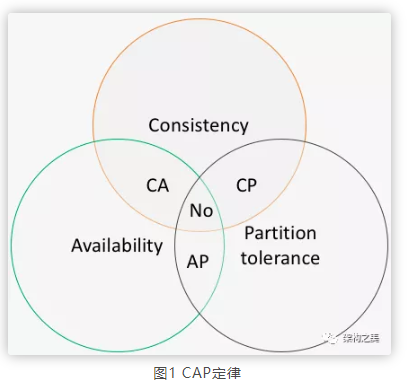
CA :没有网络分区,即:单点环境,这里我们不需要讨论
CP: 分布式环境,强制一致性
AP:分布式环境,最终一致性
分布式锁的本质
通过业务需求剖析业务背后的本质,是架构师需要具备的核心能力之一。
分布式锁的本质是对共享资源串行化处理。
我们要保证同一把分布式锁的申请在同一时刻只能有一个服务拿到此锁,因此从CAP模型底层分析,分布式锁是CP模型。
一切脱离场景谈架构都是耍流氓,特别是脱离业务场景。业务场景分为2类:追求数据强一致性场景、追求数据最终一致性场景。
数据强一致性场景比如金融、电商交易等,使用分布式锁时需要使用CP模型,不然就会出现支付去重失败等重大问题,此时公司离破产只差用户一个大请求;数据最终一致性场景比如微信发消息等,在使用分布式锁时使用AP模型较优雅,比如对用户发送消息(今晚有空吗?约个饭)的去重,极端情况下使用分布式锁去重失败,也就是消息发送到对方2次,反而会增加彼此之间的感情,本来要拒绝邀请的,由于收到2次邀请消息,结果就不好意思拒绝了。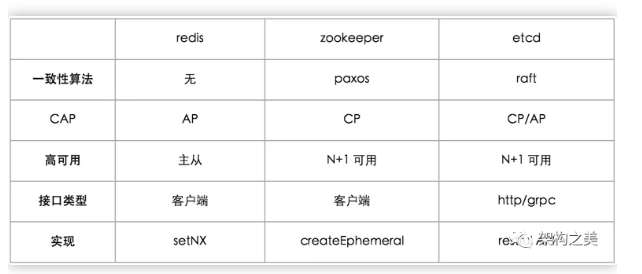
从架构设计哲学层面分析,分布式锁本质上是CP模型。一切脱离场景谈架构设计都是耍流氓,因此我们需要针对业务场景的不同,选用优雅的分布式锁实现,在追求数据强一致性的业务场景中,选用CP存储模型,在追求数据最终一致性的业务场景中,选用AP存储模型。
具体实现
方法一:redis
Redis 2.6.12及以上的版本:Set 1009 100 NX PX 10000 // 设置key为1009的value为100,仅当key不存在时设置成功,并且设置key的生存时间为10000毫秒
或者:Set 1009 100 NX EX 10 // 设置key为1009的value为100,仅当key不存在时设置成功,并且设置key的生存时间为10秒
Redis 2.6.12下的版本(redis事务):
1 | MULTI; |
redis 优缺点
- 优:实现简单
- 缺:
- redis 如果是单节点有 单点故障问题
- redis 如果使用主从模式的集群部署,Sentinal哨兵机制进行主从切换时,可能会造成数据不一致
- CAP模型: redis集群主从模式是AP模型
方法二:etcd
etcd有V2和V3两种接口:V2接口可以使用http直接访问,天然客户端物理解耦,但需要自动续租保证锁的完整性。V3接口默认grpc形式,是长链接机制,天然续租,但grpc有客户端依赖要求。可以根据场景要求,适度选择合适版本接口。
1 | 锁参数有: |
v2:
1 | 取锁:curl http://ip:port/v2/keys/锁名 -XPUT -d ttl=10 -d prevExits=false -d value=锁值 |
v3 python 客户端:
1 | etcd3.client() |
1 | etcd = etcd3.client() |
汇总
参考: https://mp.weixin.qq.com/s/38tvREH-wv5J2tuB9hPmEQ
经过以上分析,可以知道,如果需要在并发中控制共享资源的申请,必须把并发变成串行化操作,锁是一个必然的选择。怎么选择需要进行一个衡量,以下是各方面的对比:
| 锁的实现 | 使用难度 | 能够解决的问题 | 可重入 | 超时 | 阻塞 | 具体应用 |
|---|---|---|---|---|---|---|
| 线程锁 | 低 | 单进程多线程 | 默认不支持 | 默认不支持 | 不支持 | threading.lock() |
| 进程锁 | 低 | 单进程多线程,多进程 | 默认不支持 | 默认不支持 | 支持 | fcntl.lockf() |
| 数据库锁 | 高 | 单进程多线程,单进程多线程,分布式 | 默认不支持 | 不支持 | 不支持 | mysql 悲观锁 |
| 分布式锁 | 中 | 单进程多线程,单进程多线程,分布式 | 支持 | 支持 | 支持 | etcd/redis/zookeeper |
在以上列表中,数据库锁是最不推荐使用的。因为数据库锁会降低吞吐量以及死锁可能带来的问题。
